Networking for Distributed Inference in llm-d





Networking: The Critical Path in P/D Disaggregation
llm-d's prefill-decode disaggregation unlocks significant efficiency gains by separating compute-heavy prefill from memory-bandwidth-heavy decode onto dedicated GPU pools. But it introduces a hard dependency on the network: the KV Cache must be transferred from prefill to decode before the first token can be generated. This transfer time lands directly on the Time to First Token (TTFT) — making networking a first-order concern for end-to-end inference latency.
This post dives into llm-d's networking stack — how it works today and how it's evolving in collaboration with NVIDIA.
Overview
llm-d relies on NIXL (NVIDIA Inference Xfer Library) to perform KV Cache transfers between prefill and decode workers. NIXL exposes a unified API for transfers, abstracting the underlying transfer library behind — UCX over RDMA network, libfabric over AWS EFA, and other backends. This lets vLLM initiate transfers without worrying about the specifics of the network fabric or the transport (RDMA, TCP, etc.). Building on NIXL gives llm-d several properties out of the box:
- Unified abstraction: a single API that works across diverse accelerators (CUDA, ROCm, XPUs), network fabrics/protocols (InfiniBand, RoCE, EFA, TCP), memory types (GPU VRAM, CPU DRAM), and storage types (local SSD, remote storage such as HF3FS, S3, etc.) — making llm-d easily portable across cloud providers and on-premises deployments.
- Modular and extensible: NIXL's plugin architecture lets new transport and device backends be added without modifying the core library or llm-d, so that llm-d can support evolving deployment scenarios.
On top of NIXL, llm-d adds cluster-level services that bridge what NIXL can provide in terms of transfer library, and end-to-end AI inference performance:
- Tuning across the stack: each backend (UCX, UCCL, libfabric, ...) auto-tunes for its target environment, but a real deployment still depends on RDMA parameters, NIC affinity, GPU topology, multi-rail configuration, MTU, etc. llm-d provides validated defaults and enables per-deployment customization of the NIXL backends.
- Observability: llm-d provides a unified dashboard collecting NIXL's telemetry (transfer-time, transfer throughput, etc.) and application-level performance (TTFT, E2E latency, etc.) enabling operators to detect and diagnose failures.
- Per-cluster verification: performance characteristics differ across GPU platforms (NVIDIA H200, AMD MI300X, Intel Gaudi), interconnects (NVLink, PCIe, InfiniBand, Ethernet), and NICs (ConnectX-7, Broadcom, AWS EFA). llm-d provides preflight checks and benchmark tooling so each cluster can establish and track its own baseline.
Design of NIXL and Future Roadmap
The earlier NIXL blog post covers the general NIXL model: agents register memory or storage regions, exchange the metadata needed for access, and issue nonblocking transfers through a unified descriptor API. This post focuses on the backend side of that architecture, and in particular on how the UCCL backend brings UCCL P2P into NIXL for GPU memory transfers used in distributed inference. The same backend architecture also supports storage plugins for use cases such as checkpointing and KV cache offload/reload, across file, block, or object storage.
NIXL backends are platform-specific implementations behind a common southbound plugin interface. This lets each backend use the native capabilities of its target environment, instead of forcing every transport into a least-common-denominator path: Libfabric can optimize around OFI/EFA-style cloud RDMA deployments, Azure Blob can map NIXL transfers onto Azure object storage, and UCCL can bring its software-controlled GPU networking stack into NIXL.
A backend mainly declares its capabilities, such as supported memory types, local or remote transfer support, and notification support, then implements clean primitives for registration, metadata serialization/loading, connection handling where needed, and prepare/post (start)/check/release transfer operations. NIXL handles the surrounding agent machinery: plugin discovery and loading, descriptor validation, metadata encapsulation and exchange, backend selection, and the asynchronous request lifecycle. NIXL also provides default agent-level telemetry independent of the selected backend, including registration sizes, transfer bytes and request counts, post and completion timing, and error counts. Additional observability capabilities are being discussed, such as notifying users when NIXL observes sustained performance degradation or exposing more infrastructure-level signals alongside NIXL metrics.
How does llm-d work with NIXL
NIXL PD Connector
NixlConnector is the core KV-cache transfer connector in vLLM's disaggregated serving architecture. It operates in a pull-based model: the decode worker (D) fetches KV cache blocks directly from the prefill worker's (P) GPU memory via one-sided RDMA p2p READs.
At the request level, a routing proxy coordinates P and D. Connections between P and D are established lazily (as shown in Figure 1): the first time D sees an unknown P engine it performs a background handshake that exchanges metadata over ZMQ, validates a compatibility hash, and bootstraps the RDMA path — without blocking the engine loop. New instances are paired automatically following the same mechanism, with no centralized service-discovery plane required.
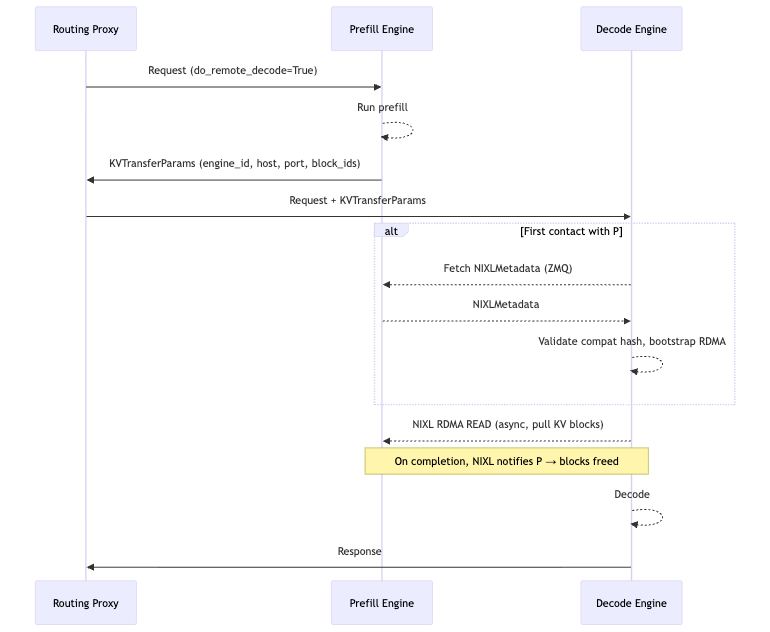 Figure 1: Timeline diagram of how prefill and decode coordinate with routing proxy and transfer KV Cache.
Figure 1: Timeline diagram of how prefill and decode coordinate with routing proxy and transfer KV Cache.
Once connected, D posts an asynchronous NIXL READ and returns immediately. On completion, NIXL notifies P to free the blocks. Transfers are zero-copy — NIXL reads directly from P's KV cache into D's KV cache with no staging buffers, so zero extra bytes are moved regardless of the parallelism configuration. The connector works out of the box with vLLM optimizations such as prefix caching (D skips blocks it already holds, avoiding RDMA transfers entirely on a full cache hit), chunked prefill, data parallelism, and CPU host-buffer offloading.
Several additional features are built on top of this core flow:
- Heterogeneous tensor parallelism. P and D can run with different TP sizes, giving operators an extra scaling knob to independently tune each phase. Each D worker dynamically computes which remote TP rank(s) to read from and fetches the appropriate tensor slice, with no intermediate copies or extra bytes transferred. Different KV block sizes across P and D are also supported.
- Hybrid Memory Allocator (HMA) support.
NixlConnectorintegrates with vLLM's hybrid memory allocator, enabling disaggregated serving for architectures that mix attention and SSM layers (e.g. Jamba, Mamba-based hybrids). Attention KV cache blocks and SSM convolutional state are each transferred directly between the corresponding memory regions with no extra copies or staging. - Fault tolerance. P holds KV blocks under a configurable lease (
kv_lease_duration) with periodic heartbeat extensions from D, so blocks are freed automatically if D crashes — preventing memory stranding without a liveness protocol. D-side KV load failures (e.g. a crashed P instance) are handled by thekv_load_failure_policy:fail(default) returns an error immediately, whilerecomputefalls back to local prefill on D. On scale-down, vLLM's abort path sends NIXL notifications to free remote blocks; on scale-up, lazy handshake means new pods become available without any coordinated rollout.
UCCL Backend for NIXL
UCX supports the current use-case of KV Cache transfers across heterogeneous hardware, but the growing diversity of transports and accelerators makes broad hardware support increasingly challenging. UCCL (Unified Collective Communication Library) is a new communication library designed to provide efficient, portable GPU networking for AI inference and training, including support for some emerging hardware platforms outside UCX's current scope. In llm-d v0.5, we have integrated our contribution of the UCCL backend into the NIXL transport library and we have been evolving it over the months to provide feature-parity with UCX such as dynamic transport selection, local (intra-node) transfers and performance optimizations.
UCCL exposes a point-to-point (P2P) transfer engine designed for KV cache and weight-transfer style traffic. This is the engine that the NIXL backend builds on, providing SM-free data movement and GPU-NIC topology awareness. It additionally provides a host-resident transport that runs fine-grained flow splitting, path selection, congestion control, and loss recovery in software while keeping bulk data on the GPUDirect/RDMA path. UCCL also provides a unified abstraction over vendor-specific collectives (NCCL, RCCL, etc.) and expert parallelism (EP), but those are outside the scope of this NIXL backend.
Performance Comparison of various Transport Backends in NIXL
We evaluate three NIXL transport backends — UCCL, UCX, and Mooncake — across three network transports: 100G RoCE, 400G NVIDIA Quantum-2 InfiniBand fabric, and 100G TCP. Mooncake is a KV cache transfer engine developed by Moonshot AI, designed for disaggregated LLM inference. It is supported as a backend plugin by NIXL. Mooncake exposes a high-performance transfer layer over RDMA and TCP, and serves as the transfer backbone in Moonshot's production Kimi serving infrastructure.
We used nixlbench as the benchmark, which includes measurement of the latency of bulk tensor transfers across GPU nodes, a workload representative of KV-cache migration in distributed LLM inference (prefill–decode disaggregation).
We tested transfers spanning 1–8 GB of total payload, reflecting KV Cache volumes typical of medium-to-long context workloads. For RoCE and TCP transfers, we used two nodes with NVIDIA H100 GPUs, ConnectX-7 NICs (one rail per GPU at 100 Gb/s, partitioned via SR-IOV for the 100 Gb/s configurations). RoCE and TCP modes use the same NICs; only the configured transport differs. For InfiniBand, we used two nodes with NVIDIA H200 GPUs connected using a NVIDIA Quantum-2 400 Gb/s InfiniBand network.
RDMA Transport (RoCE & InfiniBand)
For RDMA, we test batch sizes of 1,000 and 10,000. In nixlbench, batch size controls the number of memory descriptors posted per transfer while the total payload size is the same — so a larger batch means each block is smaller, and the per-block transfer overhead is amortized over fewer bytes. This setup is representative of how vLLM handles KV cache: PagedAttention allocates the KV cache in fixed-size paged blocks, and a single sequence's KV cache can be spread across many non-contiguous pages on the GPU.
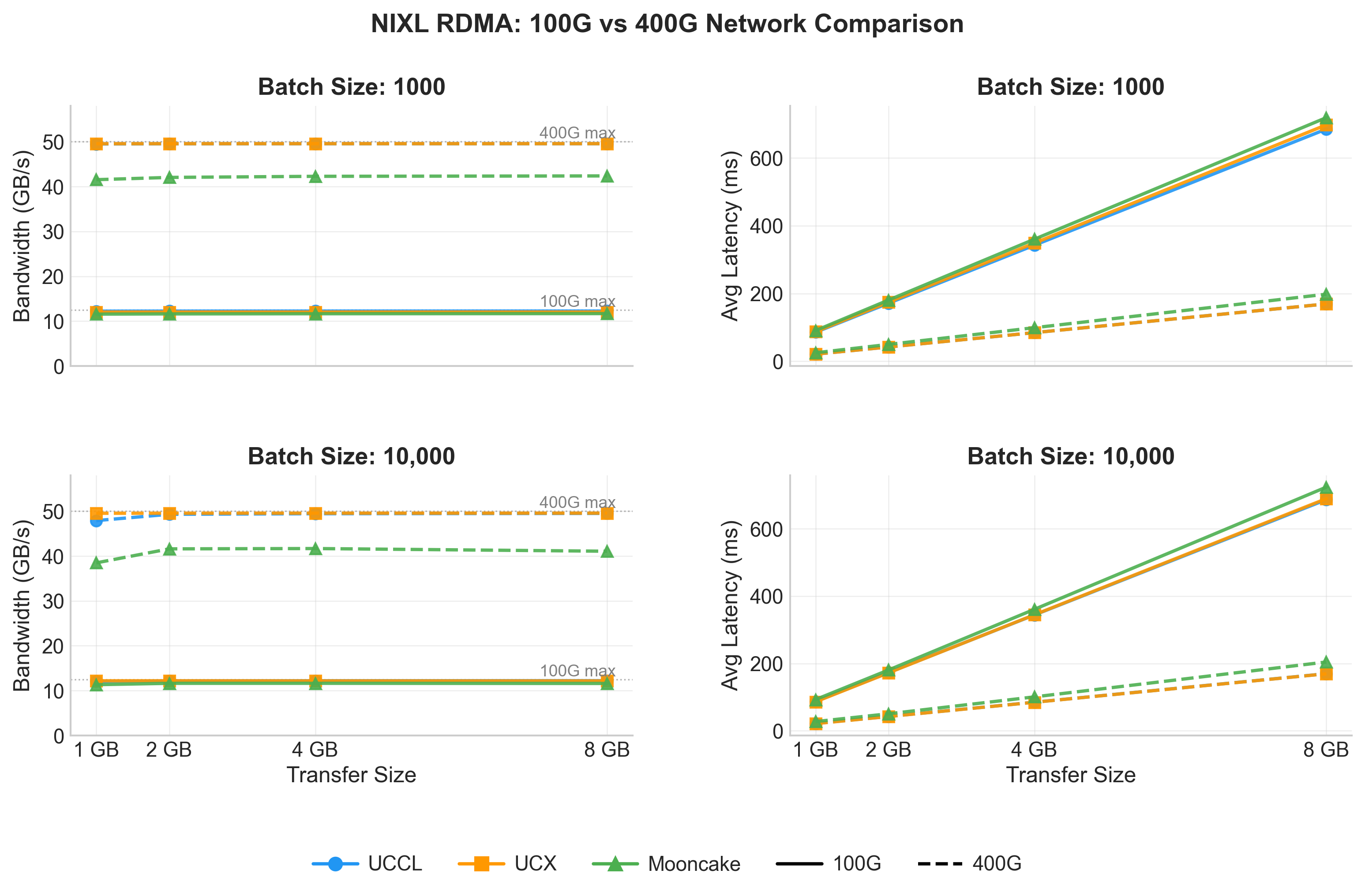 Figure 2: GPU-to-GPU Transfer throughput and latency comparison of UCCL, UCX and Mooncake backend of NIXL over 100G (solid lines), and 400G (dotted lines) InfiniBand RDMA networks.
Figure 2: GPU-to-GPU Transfer throughput and latency comparison of UCCL, UCX and Mooncake backend of NIXL over 100G (solid lines), and 400G (dotted lines) InfiniBand RDMA networks.
100G RoCE network. On the 100GbE RoCE network, UCCL, UCX, and Mooncake all converge to roughly 12.0–12.2 GB/s — within 3% of the 12.5 GB/s theoretical line rate (without considering packet header overheads) for both batch sizes as shown in Figure 2. At this network speed, we can easily saturate the link and the choice of backend is effectively invisible in the bandwidth numbers, with only minor differences in latency.
400G InfiniBand network. When we move to the 400 Gb/s fabric and keep blocks relatively large (1–8 MB, batch of 1000), UCCL and UCX both achieve ~49.5 GB/s (≈99% of the 50 GB/s line rate). We had to patch Mooncake to fix its topology detection in this cluster to ensure that it picks the right interface. Mooncake saturates at ~42 GB/s, roughly 84% of line rate — the gap is consistent with its higher per-block posting latency for read operations (~2–17 ms of accumulated post time per batch, versus ~12 µs and ~283 µs for UCCL and UCX respectively). The posting latency blocks the reader (decode worker) in its critical path, thus increasing the overall transfer time.
With the total transfer size fixed and the batch increased to 10,000, each individual block is much smaller and the per-block software overhead — descriptor preparation, posting, completion handling — is invoked far more frequently, and the raw network time per block shrinks to a few microseconds. The backends separate clearly:
- Both UCX and UCCL maintain ~49.5 GB/s across all transfer sizes, essentially matching their moderate-batch behavior and saturating the 400G link.
- Mooncake stays flat around ~38–42 GB/s, limited by the same per-block post latency that capped it at moderate batch sizes.
TCP Transport
TCP bandwidth is inherently lower than RDMA: it is two-sided, typically incurs extra memory copies and potentially CPU and kernel (e.g. Linux) involvement in the data path. However, in some deployments it remains the only option due to deployment constraints. Hence, a viable transport option remains crucial in these deployments. The three backends behave very differently here. For GPU-to-GPU transfers, UCCL provides reasonable efficiency by achieving approximately 4.7–4.9 GB/s (~39 Gbps out of 100G), while UCX manages 0.55 GB/s (~4.4 Gbps) and Mooncake does not support GPU-to-GPU TCP transfers. We provide the reasons in the next subsection.
GPU-to-GPU. This scenario of GPU-to-GPU transfers over TCP transport is where UCCL stands out the most. UCCL transfers 1 GB in 211 ms (avg) with a P99 of 217 ms — stable and consistent. UCX takes 1.8 s for the same transfer, nearly 9× slower, degrading further to 14.4 s at 8 GB (Figure 3). While UCX does not provide specific optimizations for GPU-to-GPU transfers over TCP, UCCL leverages NCCL's CUDA kernels in their send/recv APIs, which chunk a single transfer into multiple transfers for GPU-to-CPU and pipeline the network transfer over TCP. We observed that the Mooncake backend lacked support for GPU-to-GPU transfers over TCP.
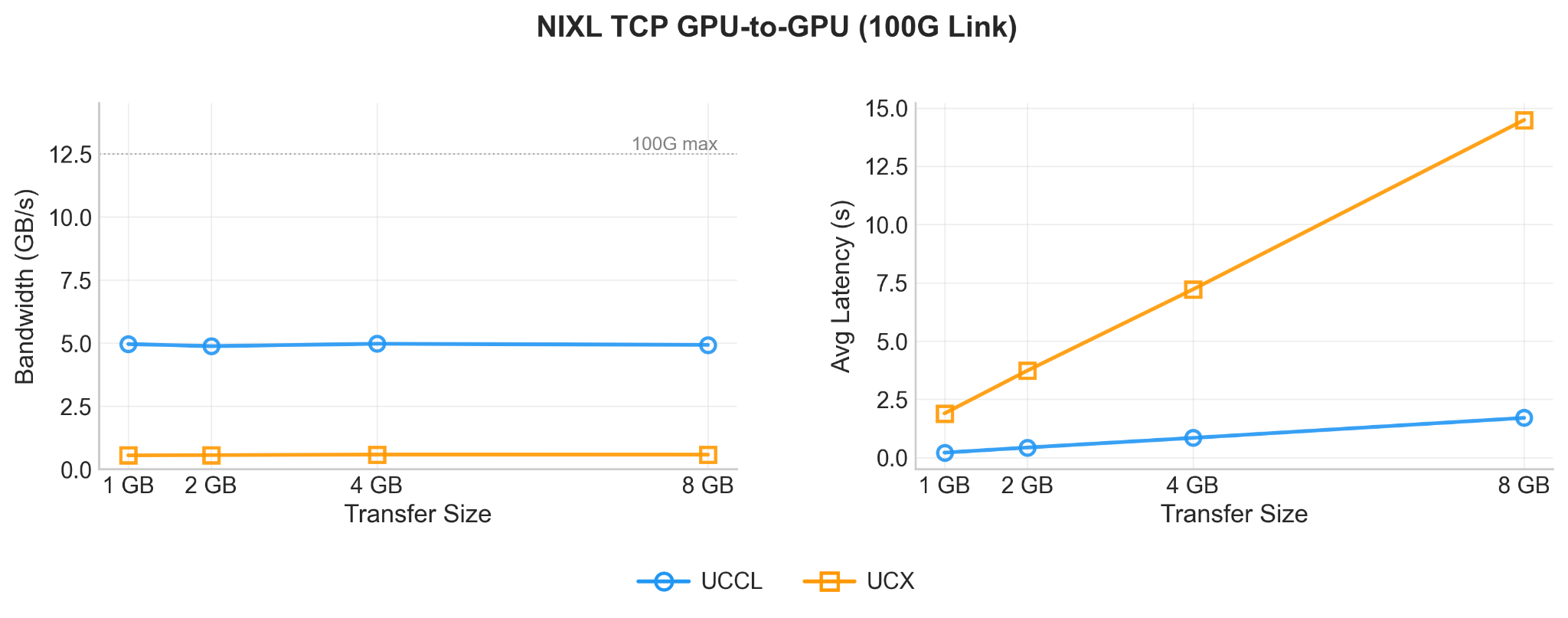 Figure 3: GPU-to-GPU Transfer latency comparison of the UCCL, UCX and Mooncake backends of NIXL over 100G TCP Network.
Figure 3: GPU-to-GPU Transfer latency comparison of the UCCL, UCX and Mooncake backends of NIXL over 100G TCP Network.
CPU-to-CPU. We also perform data transfers of buffers located in host memory because many KV cache management strategies offload cached context to host memory for later reuse, making the CPU-to-CPU path a part of the data transfer. This also isolates the TCP transport overhead from the intra-node (GPU-to-CPU) transfer overhead.
At 1 GB, UCCL completes in 216 ms, UCX in 263 ms (22% slower), and Mooncake in 298 ms (38% slower) as shown in Figure 4. The relative ordering is consistent across all transfer sizes: UCCL sustains ~4.9 GB/s, UCX ~4 GB/s and Mooncake ~3.5 GB/s. We notice UCX occasionally spikes in P99 latency for larger transfers.
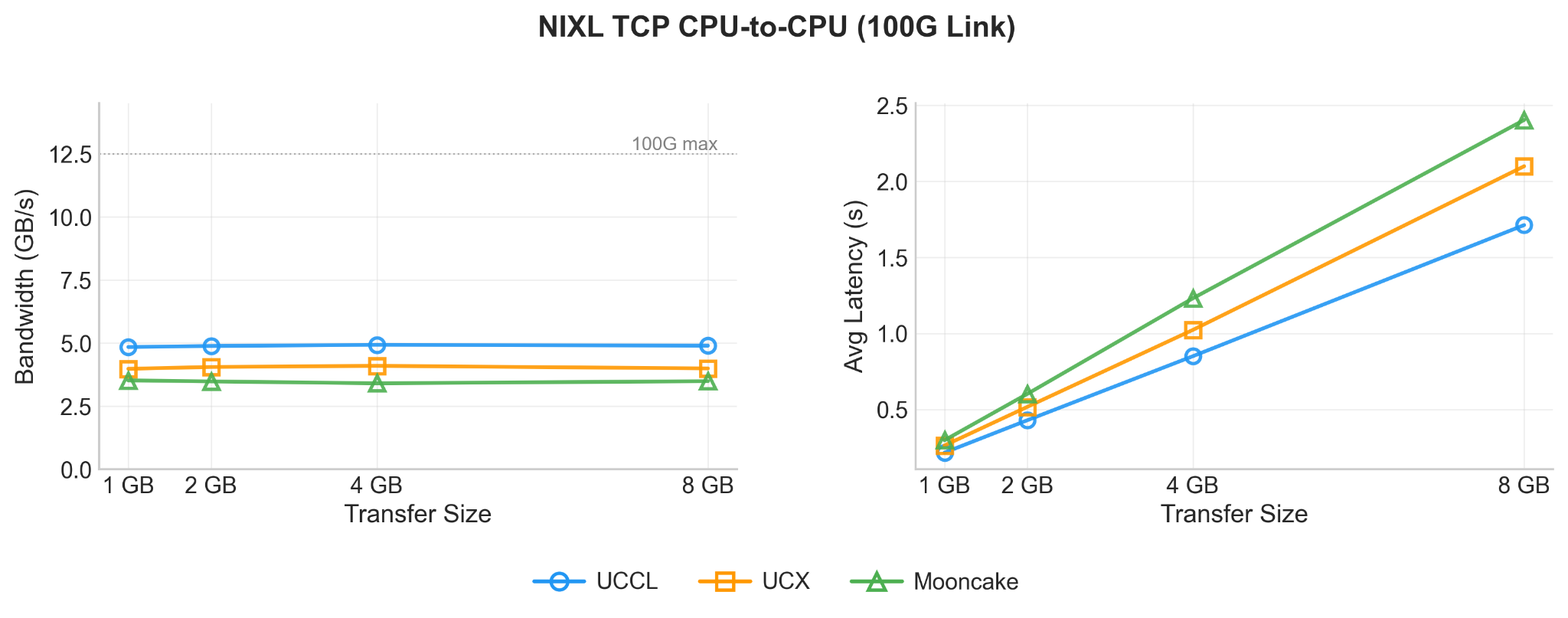 Figure 4: CPU-to-CPU Transfer latency comparison of the UCCL, UCX and Mooncake backends of NIXL over 100G TCP Network.
Figure 4: CPU-to-CPU Transfer latency comparison of the UCCL, UCX and Mooncake backends of NIXL over 100G TCP Network.
Verifying Networking in a Deployed llm-d Cluster
The benchmarking numbers above represent what the fabric can deliver. In a real deployment, the bandwidth llm-d actually sees is determined by a long chain of choices outside NIXL: pod scheduling, kernel and driver versions, and environment configuration. A small misconfiguration in any of these can silently cost half the bandwidth — and the symptom typically shows up as elevated TTFT, not as an obvious networking error. To close the gap between benchmark conditions and production behavior, llm-d operators need a way to validate the actual network path before vLLM starts serving traffic. To make this easier, we are building tooling that lets operators validate the network health directly from within the pods where llm-d will actually run, with minimal extra setup. This section describes the current flow.
Pre-flight Checks
To run tests before vLLM is started by llm-d, we use a "preflight" check script. The script gates execution of vLLM by running just before it starts: if all preflight checks succeed, the vLLM process inside the pod starts as before. The preflight checks are designed to run quickly so they do not materially delay llm-d model execution (at most a few seconds added).
However, if there are problems with Kubernetes pod networking or GPU configuration, the script may exit with a non-zero status, alarming the user, preventing vLLM from running and causing the pod to terminate so that Kubernetes can reschedule it — hopefully onto a node whose hardware resources satisfy the preflight requirements. This works by modifying the pod container startup to invoke our preflight script just before vLLM starts (it uses && to stop vllm serve if any preflight check fails):
containers:
- args:
- "... python3 llm-d-preflight-checks.py && vllm serve /model-cache/models/…"
The preflight script can also pause execution if more complex networking tests are needed. In this mode, GPU memory is fully available for testing because vLLM has not started running. This behavior is controlled by the LLMD_PREFLIGHT_CHECKS environment variable:
env:
- name: LLMD_PREFLIGHT_CHECKS
value: pause
You can see how the components work together as shown in this diagram:
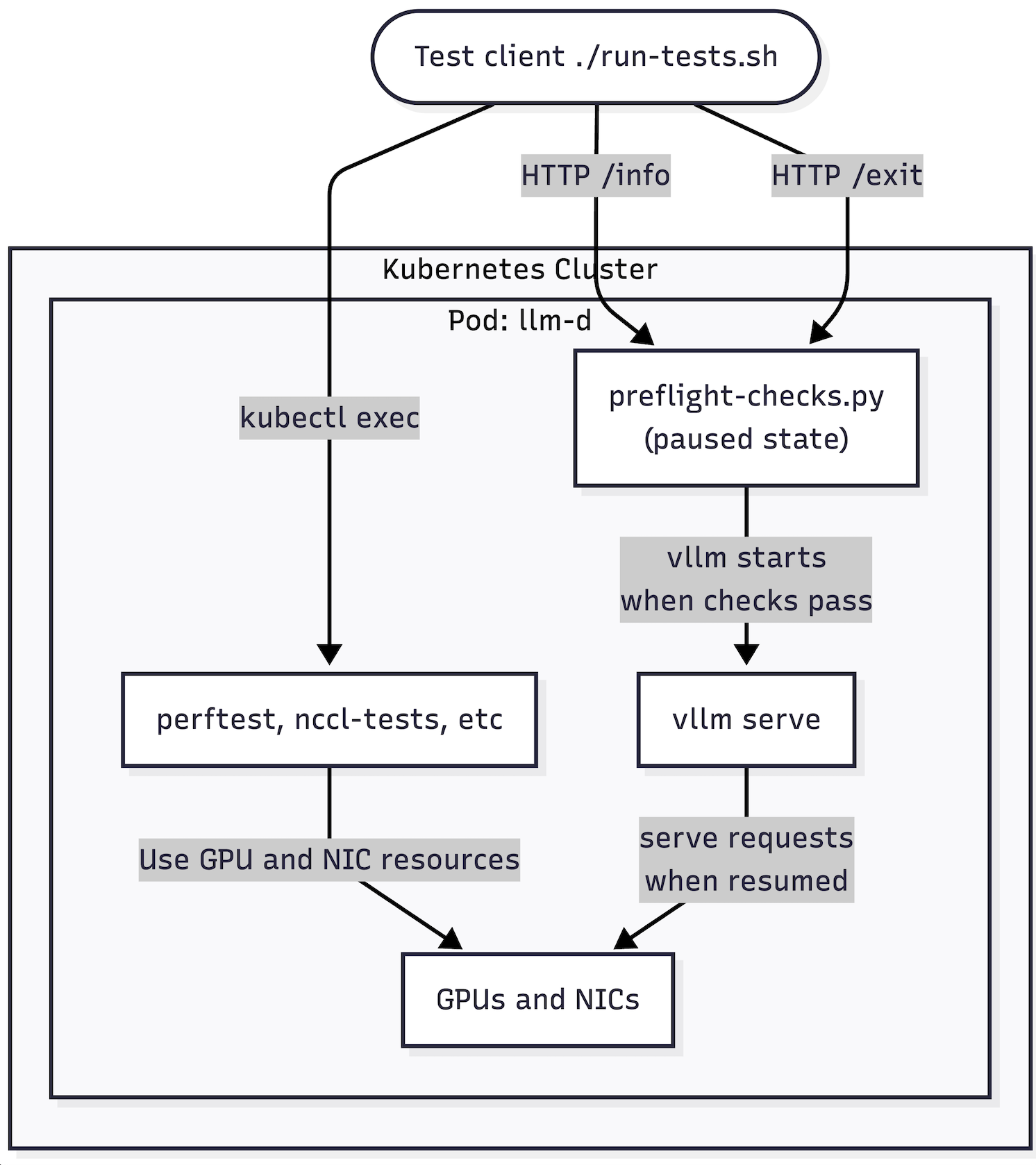
Figure 5: Methodology of running pre-flight checks: vLLM startup is waiting for preflight-check.py to finish.
Once networking tests are finished, we can signal the pods that preflight checks are complete and execution should resume into vLLM. To end the pause, we send an HTTP POST request to the /exit endpoint exposed by the preflight checks script.
How to try out runtime networking tests
The preflight check script is packaged as a skill that can be invoked from AI coding agents via /llm-d-preflight-checks in the llm-d/llm-d-pd-utils repository. We are also working to make the preflight scripts option available as an option in the llm-d Helm charts (see issue #1580).
To automate testing, we provide scripts and an AI skill that walk through running tests in llm-d pods: run-tests.sh and the /llm-d-networking-tests skill in the same repository. If you have questions about the tests or preflight checks, join the llm-d Slack and help us improve the skills and scripts.
To install skills, clone the llm-d-pd-utils GitHub repo and then copy skills into your agent's skill directory, for example for Claude Code:
AGENT_SKILLS_DIR=~/.claude/skills/
git clone https://github.com/llm-d/llm-d-pd-utils.git /tmp/llmd-skills-repo
cp -r /tmp/llmd-skills-repo/skills/* $AGENT_SKILLS_DIR
rm -rf /tmp/llmd-skills-repo
Example prompts to use with AI coding agents to run networking tests using the llm-d P/D guide:
- Follow the llm-d P/D disaggregation guide to install llm-d for quick testing with two P and one D, and use
/llm-d-preflight-checksto enable the preflight checks script. If necessary, modify pods to add the preflight checks script and the env variableLLMD_PREFLIGHT_CHECKSwithpause. - Run
/llm-d-networking-testson those pods. - Unpause all pods that have preflight checks scripts running by using the
/llm-d-preflight-checksskill, and verify that vLLM is started.
Summary
Networking is a first-class citizen for disaggregated LLM inference. As models grow larger and context windows extend to hundreds of thousands of tokens, the KV Cache transfer between prefill and decode stages becomes a significant factor in end-to-end latency. The llm-d platform provides a robust and extensible foundation for this through the following: integration with NIXL, addition of the UCCL backend for cloud-specific transports (GPUDirect TCP-X and TCP), and introduction of cluster-level preflight and runtime tests.
Key takeaways from our ongoing efforts:
- Measurement is the foundation: Before optimizing, we need to understand where we stand. Tools like nixlbench and baseline fabric measurements are essential for establishing performance targets and identifying bottlenecks.
- Backend diversity matters: Different deployments — cloud vs. on-premises, InfiniBand vs. RoCE vs. EFA — benefit from different transport backends. NIXL's plugin architecture enables this flexibility, and the addition of UCCL alongside UCX, Mooncake and the libfabric backend gives operators more choices.
- Considering KV Cache Management: KV Cache management strategies that involve CPU memory offloading require efficient heterogeneous transfer paths, which are an active area of development.
- Observability needs investment: Correlating network-level and application-level metrics across the distributed inference pipeline is key to diagnosing performance issues in production. Additionally, studying the network traffic patterns of distributed inference would help in designing better scheduling policies for large-scale agentic workloads.
- Verification belongs in the deployment loop: A correctly configured networking stack cannot be assumed — it must be validated. The preflight checks and networking test tooling we are building for llm-d let operators catch misconfigured NICs, bad RDMA bindings, and environment drifts before vLLM starts serving traffic, turning silent TTFT regressions into visible, actionable failures.
Networking is key to distributed inference and through the collaboration between the llm-d community and NVIDIA, we are working on performance improvements, better observability, and tooling that makes deployments easier to validate and tune — and we invite the broader community to join us in this effort.